Fine-tuning
Платформа Compressa позволяется дообучить LLM модель быстро и эффективно с помощью LoRA/QLoRA адаптеров или с помощью PFT. Дообучение позволяет улучшить качество ответов на конкретной бизнес-задаче, сфокусировать на определенной теме или задать формат/стиль ответов.
Важно! Дообучение модели доступно только в on-premise версии платформы, запущенной на ваших серверах.
Прежде чем переходить к дообучению, рекомендуется провести эксперименты с выбором оптимальной модели и промптингом.
Дообучение основано на фреймворке Axolotl, для мониторинга используется AIM.
Ограничения:
- FlashAttention недоступен в движке тонкой настройки
- Датасеты должны быть в формате jsonl
- 3 типа задач FT:
- LORA / QLORA
- PEFT
- DPO с LORA / QLORA
- 3 типа датасетов:
- alpaca —
{"instruction": "", "input": "", "output": ""} - chat_template —
{"messages": [{"role": "user", "content": "content"}, {"role": "assistant", "content": "content"}]} - dpo_chat_template —
{"instruction": "instruction", "input": "", "output": "chosen", "messages": [{"role": "user", "content": "content"}, {"role": "assistant", "content": "content"}], "closen": {"role": "assistant", "content": "content"}, "rejected": {"role": "assistant", "content": "content"}}
- alpaca —
- Только inference-движок vLLM для адаптеров
Подготовка
Установите DISABLE_AUTODEPLOY=TRUE в docker-compose.yaml или прервите развернутую модель после старта пода с помощью curl -X POST http://localhost:5100/v1/deploy/interrupt
Выполните
cd deploy/pod
set -a
source .env
set +a
docker compose up compressa-pod compressa-client-finetune aim-ui, aim-server -d
Чат-UI будет доступен в браузере по адресу http://localhost:8501/chat
UI для файн тюнинга будет доступен по адресу http://localhost:8501/finetune
aim-UI доступен по адресу http://localhost:43800/aim-ui
Подготовьте датасеты для дообучения.
Вы можете использовать свои собственные датасеты, загрузив их с помощью POST-запроса на http://localhost:5100/v1/datasets/upload/, пример есть в packages/pod/scripts/exampes_finetune.
Или вы можете загрузить датасеты с HuggingFace с помощью POST-запроса на http://localhost:5100/v1/datasets/add/?name=%HF_REPO_ID%
После загрузки или добавления ваши датасеты будут находиться в папке хоста DATASET_PATH и могут быть просмотрены с помощью GET-запроса на http://localhost:5100/v1/datasets
Fine Tuning
Кастомный конфиг
Вы можете использовать свой собственный .yaml файл конфига (рекомендуется, особенно для обучения PFT с разморозкой параметров, так как имена слоёв отличаются у разных моделей). Примеры доступны в Axolotl examples
- Выберите датасет из
http://localhost:5100/v1/datasets - Выберите модель из
http://localhost:5100/v1/finetune/models - Важно: доступны будут только модели с task=llm!
- Отредактируйте base_model и dataset.path в вашем конфиге
- Запустите процесс обучения:
import requests
url = "http://localhost:5100/v1/finetune/custom"
headers = {
"Authorization": "Bearer test",
}
response = requests.post(url, headers=headers, files={"config_file": open("cfg.yaml", "rb")})
print(response.json())
Вы можете проверить статус или прервать процесс через эндпоинты status и interrupt
Визуализация процесса доступна в Aim-UI http://localhost:43800/aim-ui
Адаптеры или веса дообученной модели будут доступны в отдельной папке (не затрагивает базовую модель): base_model_path_finetuned_YYYYMMDD_job_id[:8]"
Стандартный конфиг
- Можно использовать один из включённых шаблонов конфигов
- Выберите датасет из
http://localhost:5100/v1/datasets - Выберите модель из
http://localhost:5100/v1/finetune/models - Важно: доступны будут только модели с task=llm! Запустите процесс файнтюнинга:
import requests
url_finetune = "http://localhost:5100/v1/finetune/"
headers_finetune = {
"Authorization": "Bearer test",
"Content-Type": "application/json"
}
data = {
"name": "test_ft",
"model_id": "Qwen/Qwen2.5-0.5B-Instruct",
"dataset_name": "glayout_chatml.jsonl",
"training_task": "qlora",
"num_train_epochs": 10,
"learning_rate": 5e-5,
"batch_size": 2,
"lora_r": 8,
"lora_alpha": 16,
"lora_dropout": 0.05,
"quantization": "int4",
"launcher": "accelerate",
}
response = requests.post(url_finetune, headers=headers_finetune, json=data)
if response.status_code == 200:
print(f"Finetune started successfully: {response.json()}")
else:
print(f"Failed to start finetune: {response.status_code} {response.text}")
Вы можете проверить статус или прервать процесс через эндпоинты status и interrupt
Визуализация процесса доступна в Aim-UI http://localhost:43800/aim-ui
Адаптеры или веса дообученной модели будут доступны в отдельной папке (не затрагивает базовую модель): base_model_path_finetuned_YYYYMMDD_job_id[:8]"
Настоятельно рекомендуется перезапустить Pod после файнтюнинга перед merge весов или запуском нового эксперимента, чтобы избежать коллизий состояния Pod.
Запуск дообученной модели
Запуск базовой модели с адаптерами
Отредактируйте deploy_config.json:
{
"model_id": "Qwen/Qwen2.5-0.5B-Instruct",
"served_model_name": "Compressa-LLM",
"dtype": "auto",
"backend": "llm",
"task": "llm",
"adapter_ids": ["Qwen/Qwen2.5-0.5B-Instruct_finetuned_261fbfb6-22fe-4897-9f68-a28c723b072e"]
}
Запустите Pod
Merge базовой модели и адаптера
- Перезапустите pod.
- Выберите имя дообученной модели и номер чекпойнта (если None — будет и�спользован последний чекпойнт).
- При необходимости посмотрите файл
compressa-config.jsonв папке модели.
import requests
url = "http://localhost:5100/v1/finetune/merge"
headers = {
"Authorization": "Bearer test",
"Content-Type": "application/json"
}
response = requests.post(url, headers=headers,
json={
"model_id": "Qwen/Qwen2.5-0.5B-Instruct",
"lora_model_dir": "Qwen_Qwen2.5-0.5B-Instruct_finetuned_20251020_26e93c7c",
"checkpoint": None,
})
print(response.json())
Нет эндпоинтов для пров�ерки статуса и прерывания merge job, вы можете проверить статус по job_id:
curl http://localhost:5100/v1/jobs/{job_id}/status/
Слитыe веса будут доступны в отдельной папке (не затрагивает базовую модель): base_model_path_merged_finetuned_YYYYMMDD_job_id[:8]_checkpoint"
Проверьте model_id модели с помощью GET-запроса на http://localhost:5100/v1/models и отредактируйте deploy_config.json, чтобы запустить pod с моделью после merge.
{
"model_id": "Qwen/Qwen2.5-0.5B-Instruct_merged_415a70b8",
"served_model_name": "Compressa-LLM",
"dtype": "auto",
"backend": "llm",
"task": "llm"
}
Загрузка датасетов, файнтюнинг, мониторинг и merge доступны также через UI по адресу http://localhost:8501/finetune
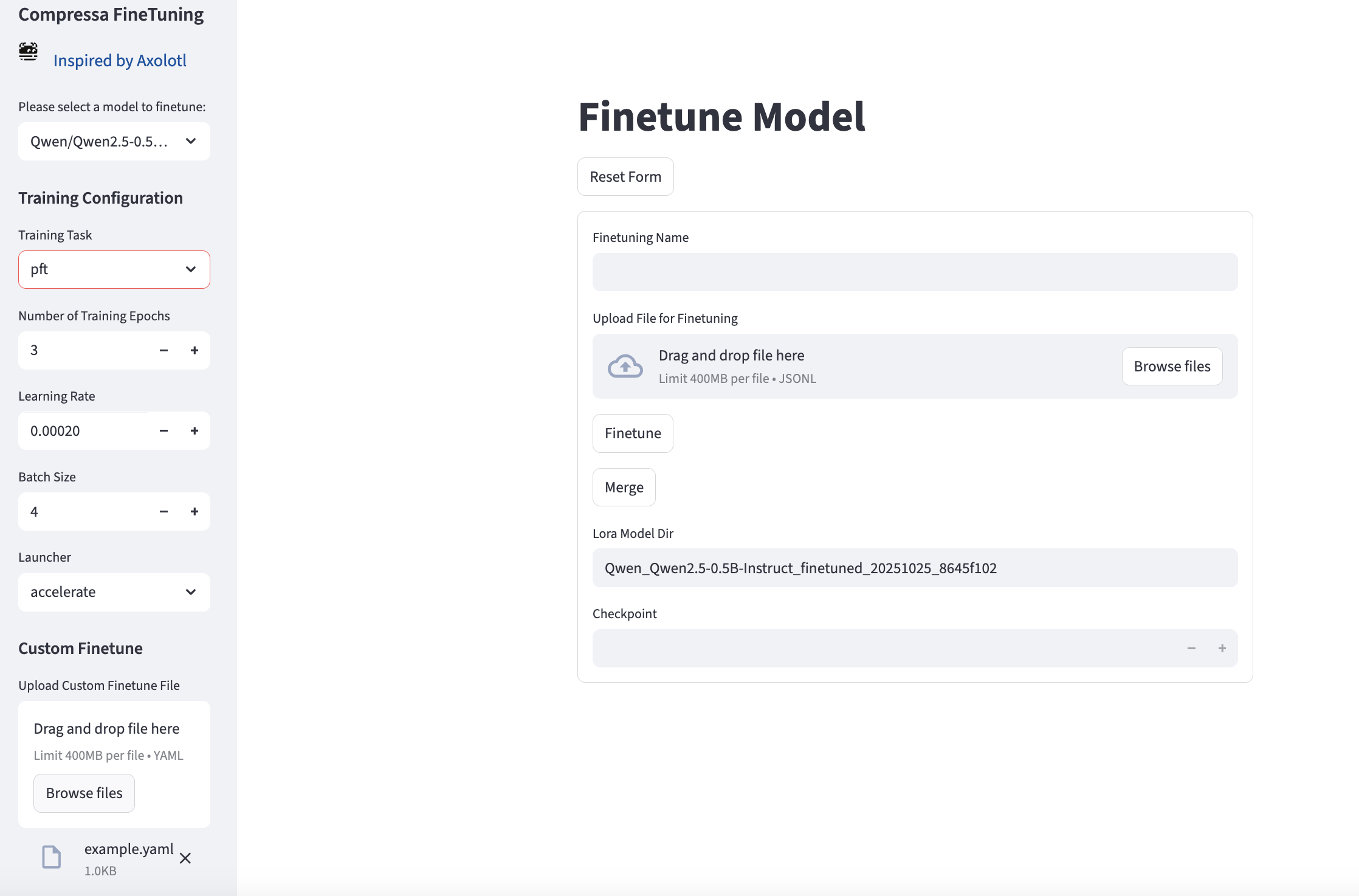
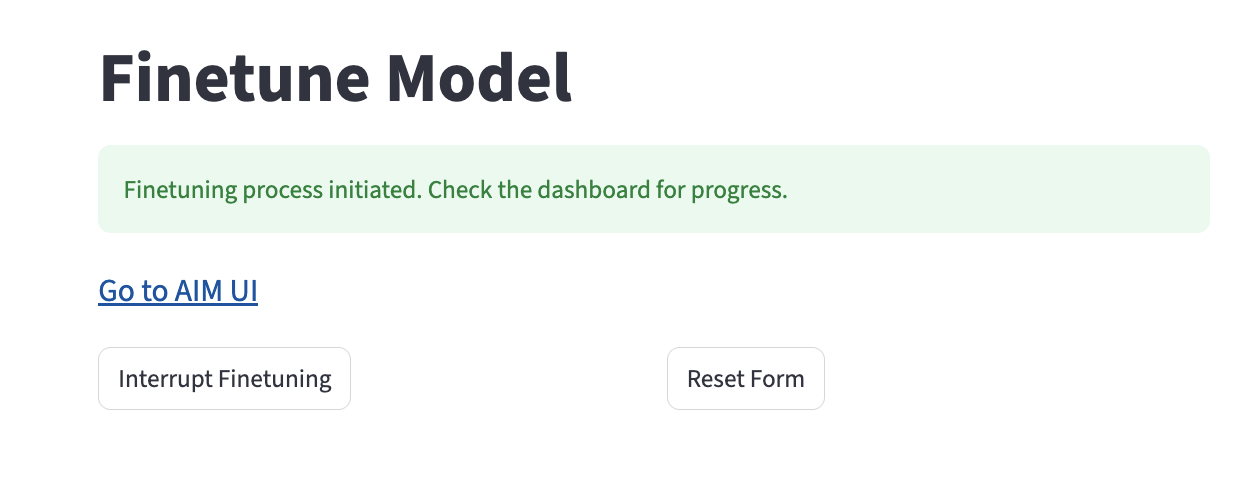
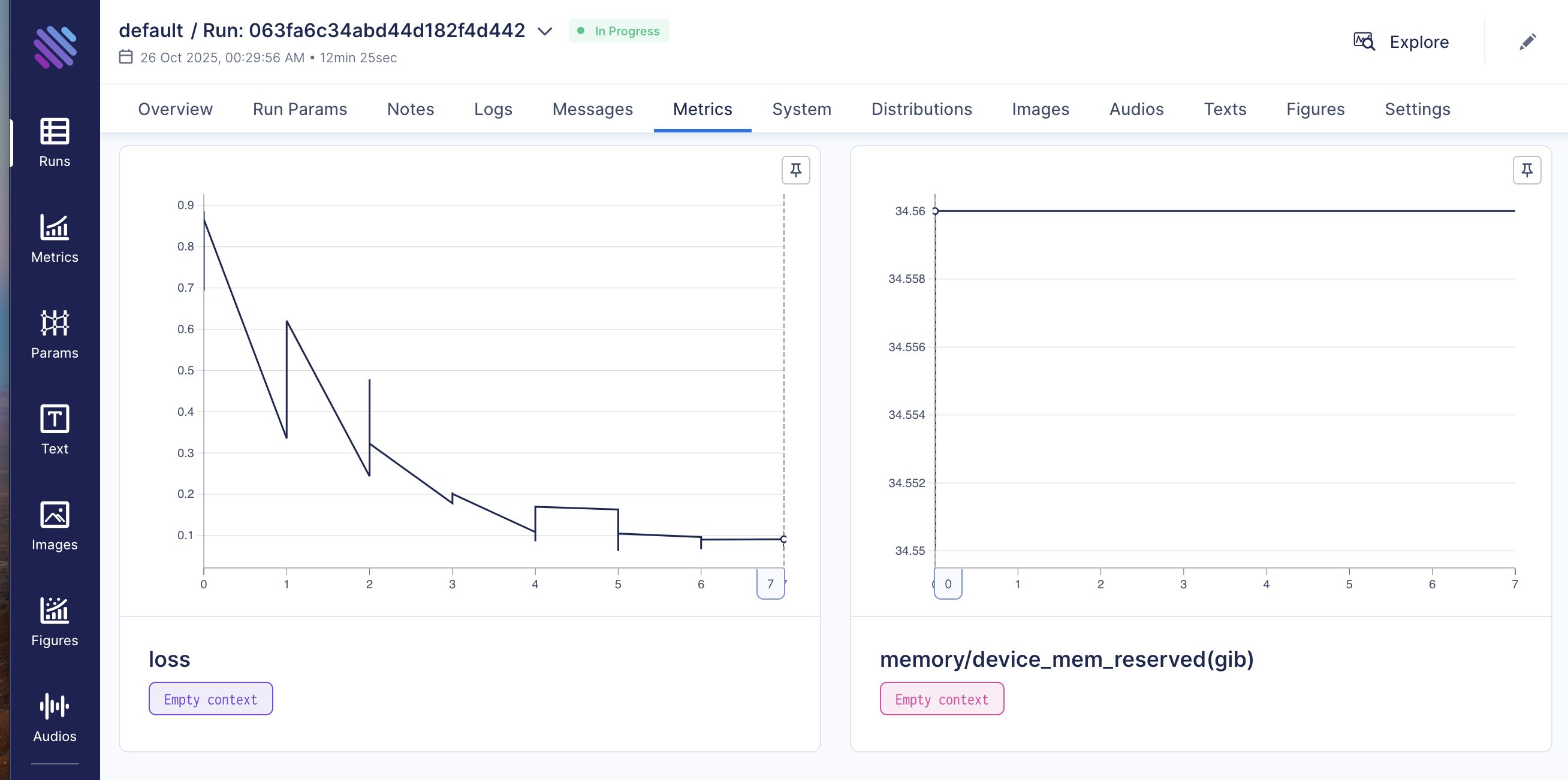
Описание REST API
Управление датасетами
GET /v1/datasets/
Получить список доступных датасетов.
Пример запроса:
curl -X 'GET' \
'http://localhost:5100/v1/datasets/' \
-H 'accept: application/json'
Пример ответа:
[
{
"id": "01be6d68-f790-434b-aa6d-5bd492aef202",
"name": "train.jsonl",
"path": "01be6d68-f790-434b-aa6d-5bd492aef202/metadata.json",
"description": null
},
{
"id": "077adb68-2b0e-481b-bd13-e8807adf625f",
"name": "train.jsonl",
"path": "077adb68-2b0e-481b-bd13-e8807adf625f/metadata.json",
"description": "My dataset 2"
}
]
POST /v1/datasets/upload/
Загрузить новый датасет (только ‘jsonl’ формат).
Параметры:
- query:
description- dataset description
Тело запроса:
- multipart/form-data:
file
Пример запроса:
curl -X 'POST' \
'http://localhost:5100/v1/datasets/upload/?description=My%20Description' \
-H 'accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-F 'file=@train.jsonl'
Пример ответа:
{
"id": "string",
"name": "string",
"path": "string",
"description": "string"
}
POST /v1/datasets/add/
Скачать новый датасет с HuggingFace.
Пример запроса:
curl -X 'POST' \
'http://localhost:5100/v1/datasets/add/?name=REPO_ID' \
-H 'accept: application/json' \
Пример ответа:
{
"id": "string",
"name": "string",
"path": "string",
"description": "string"
}
GET /v1/datasets/{dataset_id}/
Загрузить конкретный датасет по id dataset_id
Параметры:
- path:
dataset_id
Пример запроса:
curl -X 'GET' \
'http://localhost:5100/v1/datasets/01be6d68-f790-434b-aa6d-5bd492aef202/' \
-H 'accept: application/json'
Пример ответа:
file
Дообучение модели
GET /v1/finetune/models/
Получить список моделей, доступных для дообучения
Пример запроса:
curl -X 'GET' \
'http://localhost:5100/v1/finetune/models/' \
-H 'accept: application/json'
Пример ответа:
[
{
"model_id": "TheBloke/mixtral-8x7b-v0.1-AWQ",
"adapter": false,
"base_model_id": null
},
{
"model_id": "NeuralNovel/Mistral-7B-Instruct-v0.2-Neural-Story",
"adapter": false,
"base_model_id": null
}
]
POST /v1/finetune/
Запустить дообучение модели на датасете
Примеры см. выше.
GET /v1/finetune/status
Получить статус текущего процесса дообучения
Пример запроса:
curl -X 'GET' \
'http://localhost:5100/v1/finetune/status/' \
-H 'accept: application/json'
Пример ответа:
{
"id": "46c155b4-17fe-4226-9412-a77edfadc7e7",
"name": "My Adapter Training",
"model_id": "NousResearch/Llama-2-7b-chat-hf",
"dataset_id": "01be6d68-f790-434b-aa6d-5bd492aef202",
"job": {
"id": "74280be7-4723-475d-89ae-346e9017990e",
"name": "FT_NousResearch/Llama-2-7b-chat-hf_01be6d68-f790-434b-aa6d-5bd492aef202",
"status": "RUNNING",
"started_at": "2024-03-21T10:40:40.928442"
}
}
POST /v1/finetune/interrupt/
Прервать процесс дообучения
Пример запрос:
curl -X 'POST' \
'http://localhost:5100/v1/finetune/interrupt/' \
-H 'accept: application/json' \
-d ''
Пример ответа:
{
"id": "74280be7-4723-475d-89ae-346e9017990e",
"name": "FT_NousResearch/Llama-2-7b-chat-hf_01be6d68-f790-434b-aa6d-5bd492aef202",
"status": "RUNNING",
"started_at": "2024-03-21T10:40:40.928442"
}
POST /v1/finetune/merge
Выполнить Merge базовой модели и LORA адаптера.
Пример см. выше.