Quickstart: Mistral-7B On-Premises
This guide will show you how to deploy the Mistral-7B inference on a single A100-40GB GPU.
The A100-40GB GPU allows you to host the Mistral-7B without quantization.
We recommend using openchat/openchat-3.5-0106 version of the Mistral-7B.
Experiments demonstrate that this model achieves the best quality across a wide range of tasks among models of this size.
Deploy Compressa
The first step is to deploy compressa according to the instruction.
Assuming Compressa is deployed on port 8080, you can use the manager's REST API at http://localhost:8080/api to download and deploy the model.
Full details about the manager API can be found in the instruction
or on the Swagger page at http://localhost:8080/api/docs.
Download model
If you're deploying Compressa in private network without internet access that step can be skipped. Please use the instruction to download resources before deployment.
You can download the model using the following curl command:
curl -X 'POST' \
'http://localhost:8080/api/v1/models/add/?model_id=openchat%2Fopenchat-3.5-0106' \
-H 'accept: application/json' \
-d ''
Alternatively, download directly from the Swagger page by clicking Try it out:
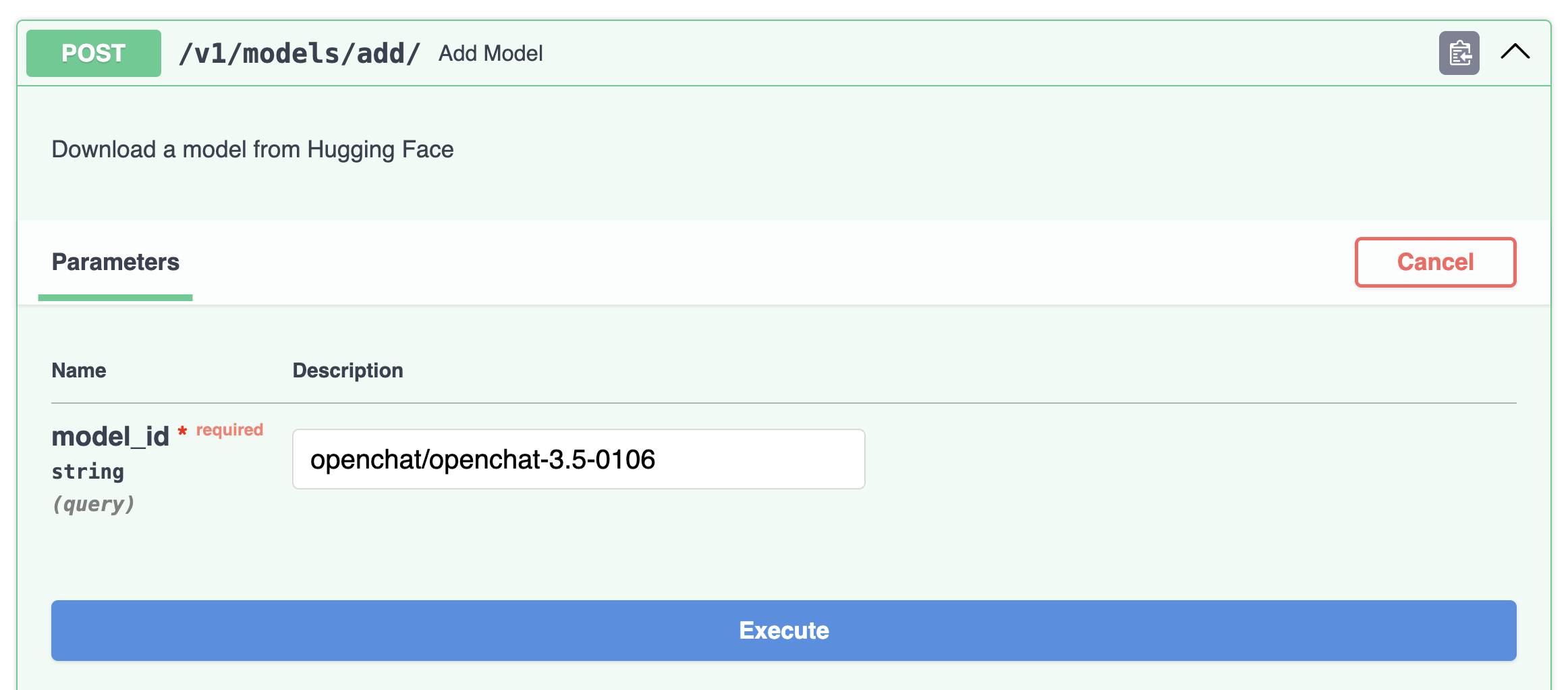
The model will be downloaded within a few minutes.
The process can be monitored from the console log or via the API.
Deploy model
You can also deploy the model using the following curl command:
curl -X 'POST' \
'http://localhost:8080/api/v1/deploy/' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model_id": "openchat/openchat-3.5-0106"
}'
Or directly from the Swagger page:
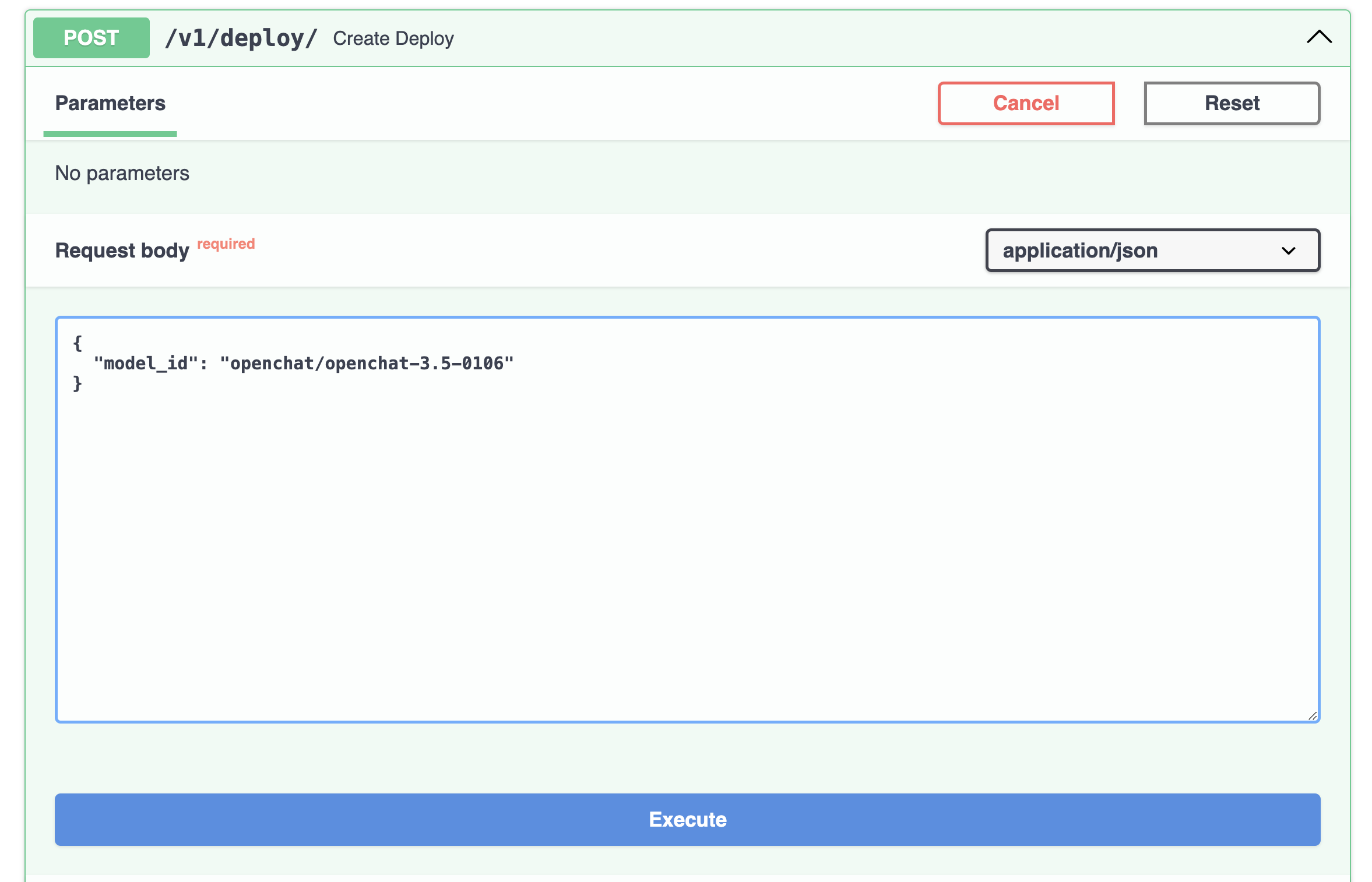
Deployment will take less than a minute.
Model access
Once the model is deployed, it will be accessible at http://localhost:8080/chat:
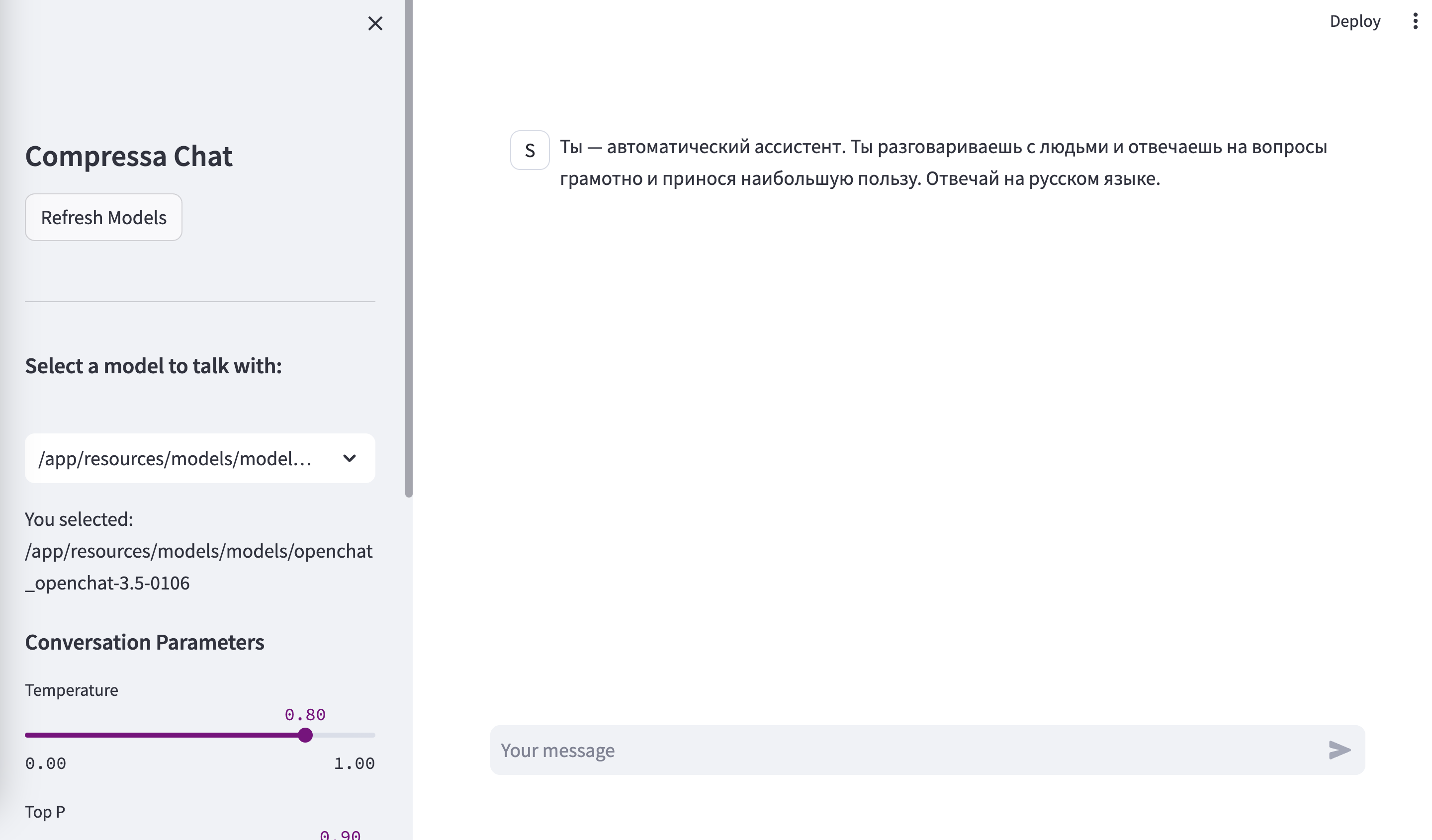
and through the OpenAI compatible API at http://localhost:8080/openai-api:
curl -X 'GET' \
'http://localhost:8080/openai-api/v1/models'