Погружение в embeddings и семантический поиск
Языковые модели позволяют компьютерам выходить за рамки стандартного поиска по ключевым словам и находить нужные фрагменты по смыслу текста. Это называется семантическим поиском, и сегодня мы реализуем его на практике.
Применение семантического поиска выходит за рамки построения веб-поиска. С ним вы можете создать собственную поисковую систему по внуренним документам компании или помочь пользователям лучше ориентироваться в вашем FAQ. Еще один пример практического внедрения семантического поиска - рекомендации релевантных статей в блоге после прочтения одной из них.
Вот как это выглядит в формате схемы:
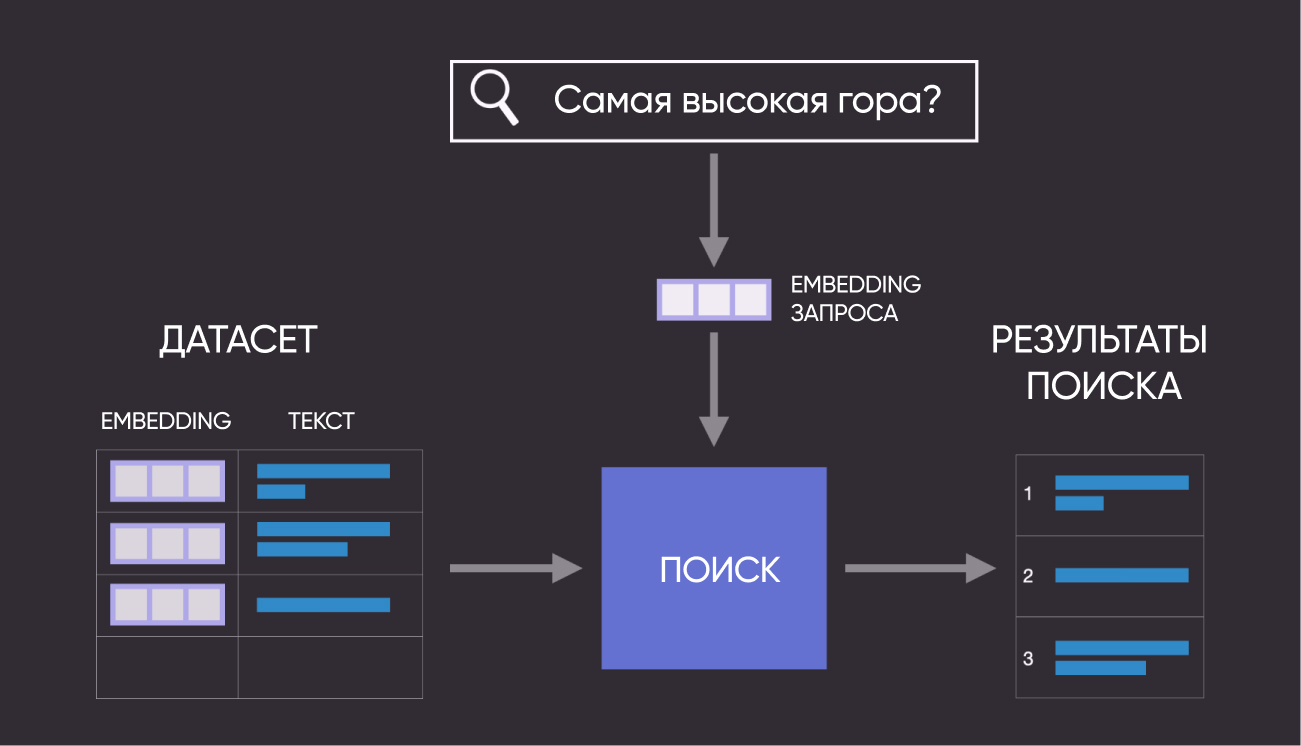
Итак, в рамках текущего гайда мы пройдем следующие шаги:
- Получим csv файл 1000 вопросов на русском
- Превратим текст в числовые embeddings
- Используем поиск по индексу и ближайшим соседям
- Визуализируем файл вопросов на основе embeddings
Весь представленный ниже код можно получить в виде .ipynb ноутбука здесь.
# Установите Compressa для создания embeddings, Umap – для уменьшения их размерности до 2 измерений;
# Altair – для визуализации, Annoy – для приблизительного поиска ближайших соседей;
#!pip install langchain
#!pip install langchain-compressa
#!pip install umap-learn
#!pip install altair
#!pip install annoy
# Возможно, у вас также не установлены какие-то из популярных пакетов
#!pip install pandas
#!pip install numpy
#!pip install tqdm
#!pip install scikit-learn
#!pip install gdown
1. Настраиваем окружение
# Импортируем библиотеки
from langchain_compressa import CompressaEmbeddings
import os
import gdown
import numpy as np
import re
import pandas as pd
from tqdm import tqdm
import altair as alt
from sklearn.metrics.pairwise import cosine_similarity
from annoy import AnnoyIndex
import umap.umap_ as umap
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', None)
Для ячейки ниже вам понадобится API ключ Compressa. Вы можете получить его после регистрации.
os.environ["COMPRESSA_API_KEY"] = "ваш_ключ"
2. Загрузите датасет с вопросами
Мы специально подготовили 1000 вопросов на русском языке для работы с ними в рамках этого гайда.
#Скачиваем датасет c google диска Сompressa
file_id = '1wRC8bKBY5W8lrXU9cTKCgAdoL0g72ANI'
url = f'https://drive.google.com/uc?id={file_id}'
gdown.download(url, '1000_ru_questions.csv', quiet=False)
# Импортируем в pandas dataframe
df = pd.read_csv(file_path)
# Проверяем, что все загрузилось корректно
df.head(10)
2. Превращаем датасет вопросов в embeddings
Следующий шаг - превратить наши текстовые вопросы в числовые embeddings.
Схематично это выглядит так:
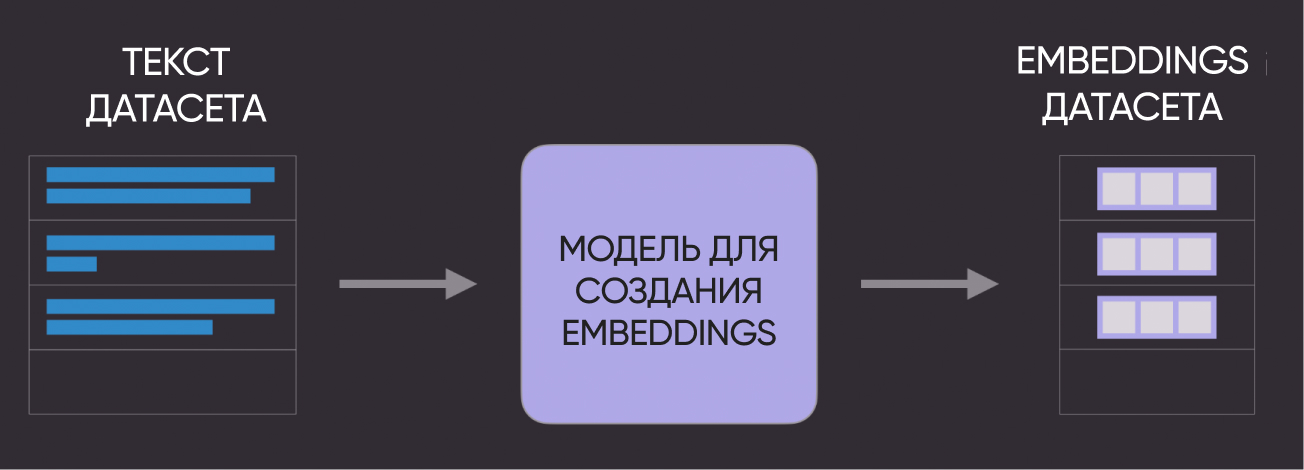
# Получаем наши embeddings
embeddings = CompressaEmbeddings(api_key=os.getenv("COMPRESSA_API_KEY"), base_url="https://compressa-api.mil-team.ru/v1")
texts = list(df['question'])
embeds = embeddings.embed_documents(texts)
# Проверяем размерность наших embeddings (напомним, что у нас 1000 вопросов)
embeds = np.array(embeds)
print(embeds.shape)
3. Используем поиск по индексу и ближайшему соседу
Еще одна схема для наглядности :)
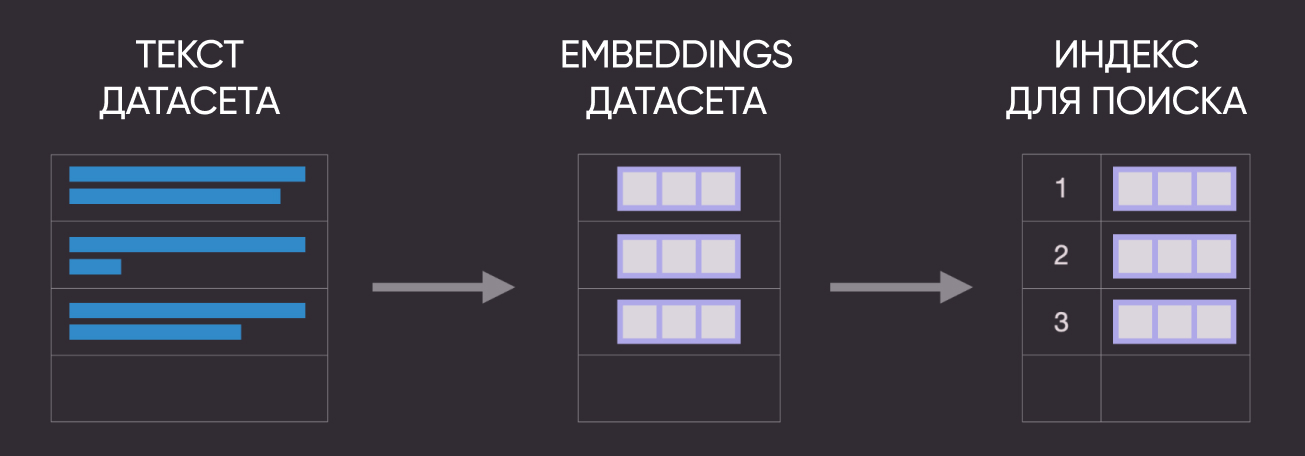 Давайте теперь используем Annoy для построения индекса, который хранит embeddings в специальном виде, оптимизированном для быстрого поиска. Этот подход хорошо масштабируется на большое количество текстов. Есть и другие решения - Faiss, ScaNN, PyNNDescent).
Давайте теперь используем Annoy для построения индекса, который хранит embeddings в специальном виде, оптимизированном для быстрого поиска. Этот подход хорошо масштабируется на большое количество текстов. Есть и другие решения - Faiss, ScaNN, PyNNDescent).
После создания индекса, можно использовать его для получения ближайших соседей для какого-то из существующих вопросов.
# Создаем поисковый индекс, передаем размер наших embeddings
search_index = AnnoyIndex(embeds.shape[1], 'angular')
# Добавляем все вектора в поисковый индекс и контрольно тестируем
for i in range(len(embeds)):
search_index.add_item(i, embeds[i])
search_index.build(10) # 10 trees
search_index.save('test.ann')
3.1. Ищем похожие по смыслу вопросы для одного примера из датасета
Если нас интересует только близость вопросов в датасете (без внешних запросов), тогда проще всего посчитать расстояние между всеми парами embeddings, которые мы получили ранее.
# Выбираем один из вопросов, чтобы найти другие, похожие на него
example_id = 109
# Достаем ближайших соседей
similar_item_ids = search_index.get_nns_by_item(example_id,10,
include_distances=True)
# Форматируем и выводим ближайшие вопросы и расстояние до них
results = pd.DataFrame(data={'вопросы': df.iloc[similar_item_ids[0]]['question'],
'расстояние': similar_item_ids[1]}).drop(example_id)
print(f"Вопрос:'{df.iloc[example_id]['question']}'\nПохожие вопросы:")
results
3.2. Ищем вопросы, похожие на запрос пользователя
Мы не ограничены поиском соседей для существующих вопросов. Если мы получаем новый запрос от пользователя, мы можем преобразовать его в embedding и найти ближайших соседей в нашем наборе данных.
query = "Какая самая высокая гора в мире?"
# Превращаем запрос в embedding
query_embed = embeddings.embed_query(query)
# Достаем близкие по смыслу вопросы с помощью индекса Annoy
similar_item_ids, distances = search_index.get_nns_by_vector(query_embed, 10, include_distances=True)
# Форматируем результаты
query_results = pd.DataFrame(data={'questions': df.iloc[similar_item_ids]['question'],
'distance': distances})
print(f"Запрос пользователя: '{query}'\nПохожие вопросы:")
print(query_results)
4. Визуализируем файл вопросов
В качестве последнего упражнения давайте отобразим вопросы из датасета на 2D графике и наглядно посмотрим на семантические связи.
# UMAP уменьшает размерность embeddings с 4096 до 2, чтобы мы могли отобразить их на графике
reducer = umap.UMAP(n_neighbors=20)
umap_embeds = reducer.fit_transform(embeds)
# Подготовим данные для построения интерактивного графика с помощью Altair
df_explore = pd.DataFrame(data={'questions': df['question']})
df_explore['x'] = umap_embeds[:,0]
df_explore['y'] = umap_embeds[:,1]
# Строим график
chart = alt.Chart(df_explore).mark_circle(size=60).encode(
x=#'x',
alt.X('x',
scale=alt.Scale(zero=False)
),
y=
alt.Y('y',
scale=alt.Scale(zero=False)
),
tooltip=['questions']
).properties(
width=700,
height=400
)
chart.interactive()
Поводите курсором по точкам, чтобы увидеть текст. Видите ли вы некоторые закономерности в сгруппированных точках? Похожие по смыслу вопросы или вопросы на схожие темы?
Поздравляем! На этом завершается наше вводное руководство по семантическому поиску с использованием embeddings. По мере создания поисковых продуктов, безусловно, возникнут и дополнительные вопросы (например, обработка длинных текстов или настройки для улучшения embeddings под конкретную задачу).
Начните создавать свои проекты с нашими API! Если вы хотите поделиться результатами или задать вопрос команде - вступайте в наш Телеграм чат.