Продвинутый chunking для улучшения RAG
1. Введение
Chunking — это процесс разделения длинного текста на более мелкие фрагменты, называемые чанками. В RAG (Retrieval-Augmented Generation) пайплайнах этот процесс является важным этапом, потому что именно чанки используются для создания векторных эмбеддингов и семантического поиска информации. Мы ищем самые близкие куски (чанки) под запрос пользователя, и отдаем их LLM для генерации ответа на запросы. Чем лучше нарезан документ на текстовые чанки, тем выше вероятность того, что модель сможет найти и предоставить точную и релевантную информацию.
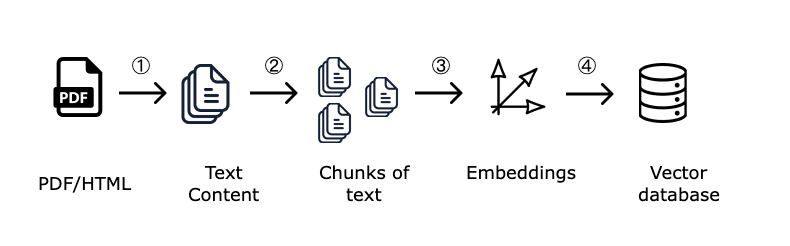
В чем сложность? Финансовые документы, такие как PDF-отчёты компаний, содержат сложную структуру: заголовки, таблицы, списки и текстовые блоки, в них сложная верстка и расположение блоков. Если обработать документы и разбить их на чанки неправильно, это негативно повлияет на качество ответа.
Цель этого гайда — продемонстрировать, как различаются результаты, когда мы используем базовую нарезку на чанки из langchain и более продвинутую нарезку CompressaChunking, которая учитывает структуру документа и например, распознает таблицы.
Наш гайд будет включать следующие шаги:
- Загрузка финансовой PDF презентации и нарезка на чанки с помощью langchain
- Повторение базового langchain RAG пайплайна из гайда "Базовый RAG за 15 минут"
- Проверка работы пайплайна на тестовых вопросах
- Улучшение качества chunking процесса
- Повторное тестирование и оценка результатов
2. Подготовка окружения
Установим и импортируем необходимые библиотеки:
#!pip install langchain
#!pip install langchain-compressa
#!pip install langchain_community
#!pip install requests
#!pip install beautifulsoup4
#!pip install gdown
#!pip install faiss-cpu - если вы запускаете на CPU
#!pip install faiss-gpu - если вы запускаете на GPU с поддержкой CUDA
import os
import requests
import gdown
from bs4 import BeautifulSoup
from langchain_compressa import CompressaEmbeddings, ChatCompressa
from langchain_core.documents import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
from langchain_community.vectorstores import FAISS
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.document_loaders import PyPDFLoader
Для ячейки ниже вам понадобится API ключ Compressa. Вы можете получить его после регистрации.
os.environ["COMPRESSA_API_KEY"] = "ваш_ключ"
# Если вы запускаете локально на Macbook, укажите также следующие переменные в окружении
# os.environ["TOKENIZERS_PARALLELISM"] = "false"
# os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
3. Обработка и нарезка документа (chunking) с использованием langchain
Мы будем работать с отчетной PDF презентацией за год, публично доступной на сайте компании Мвидео-Эльдорадо. Для ускорения обработки в рамках гайда, я ограничил объем презентации до 6 слайдов. Пример одного из слайдов:

Сначала загрузим PDF-файл и применим базовый chunking алгоритм с использованием стандартного инструмента langchain — RecursiveCharacterTextSplitter.
Этот инструмент просто разбивает текст по заданному количеству символов, не принимая во внимание структуру документа.
#Скачиваем нужный PDF-файл c Google диска Сompressa
file_id = '14sA1-B90nwwTZr3A9V1J0NfNpTYYguMy'
url = f'https://drive.google.com/uc?id={file_id}'
gdown.download(url, 'mvideo_report.pdf', quiet=False)
loader = PyPDFLoader("mvideo_report.pdf")
# Загружаем страницы PDF в качестве документов Langchain
documents = loader.load()
# Настраиваем параметры нарезки (chunking)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # Размер каждого чанка
chunk_overlap=20, # Добавление соседних символов к чанку
add_start_index=True
)
# Разделяемм PDF-документ на чанки
chunks = text_splitter.split_documents(documents)
# Проверяем количество чанков (должно быть 20)
print(f"Всего создано чанков: {len(chunks)}")
# Посмотрим внимательно на полученные чанки.
# Заметим, как подобная "примитивная" стратегия нарезки документов разрывает мысли между чанками.
for i, chunk in enumerate(chunks):
print(f"Чанк {i+1}:\n{chunk.page_content}\n")
4. Повторение базового langchain RAG пайплайна
Давайте повторим базовый RAG пайплайн на базе langchain, который мы уже разбирали в гайде "Базовый RAG за 15 минут". Мы просто скопируем его и не будем разбирать повторно.
Важное изменение!
Для наглядности улучшений от более продвинутой стратегии чанкинга, мы будем искать и передавать в LLM только 1, самый релевантный кусок документа.
embeddings = CompressaEmbeddings(api_key=os.getenv("COMPRESSA_API_KEY"), base_url="https://compressa-api.mil-team.ru/v1")
# Создаем и заполняем векторное хранилище
vectorstore = FAISS.from_documents(chunks, embeddings)
print("Векторное хранилище успешно создано")
# Создаем механизм поиска нужных чанков, ищем 1 самый релевантный
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": 1})
# Настраиваем LLM для генерации ответов
llm = ChatCompressa(api_key=os.getenv("COMPRESSA_API_KEY"), base_url="https://compressa-api.mil-team.ru/v1")
system_template = f"""Ты умный помощник на русском языке, который отвечает на вопросы пользователя по предоставленной информации. Используй следующую контекстную информацию,
чтобы ответить на вопрос. Если в контексте нет ответа, ответь 'Не знаю ответа на вопрос'.
Отвечай максимально точно, но по возможности кратко."""
qa_prompt = ChatPromptTemplate.from_messages([
("system", system_template),
("human", """Контекстная информация:
{context}
Вопрос: {input}
"""),
])
# Создаем цепочку для ответа на вопросы
document_chain = create_stuff_documents_chain(llm, qa_prompt)
rag_chain = create_retrieval_chain(retriever, document_chain)
def ask_question(question):
response = rag_chain.invoke({"input": question})
return response["answer"]
4. Проверка на тестовых вопросах
Посмотрим, сможет ли наш RAG-ассистент ответь на несколько вопросов по документу:
questions = [
"Что было в мае?",
"Когда стартовали продажи бренда Casarte?",
"На чем планирует фокусироваться компания в области гарантийного и пост-гарантийного обслуживания?",
"На сколько % увеличилась EBITDA год к году по МФСО 17 ?",
]
print("\nИспользование RAG пайплайна:")
for question in questions:
print(f"\nВопрос: {question}")
print(f"Ответ RAG: {ask_question(question)}")
Сравним полученные результаты с правильными ответами:
Вопрос: Что было в мае?
Правильный ответ: Группа стала крупнейшим оператором электронных отходов в России и ключевым партнёром первого в России комплекса заводов по переработке электроники «Корпорации Экополис».
Вопрос: Когда стартовали продажи бренда Casarte?
Правильный ответ: В декабре
Вопрос: На чем планирует фокусироваться компания в области гарантийного и пост-гарантийного обслуживания?
Правильный ответ: Группа планирует дополнительно фокусироваться на предостав- лении широкого спектра специализированных инструментов – продлённой гарантии, товарных страховок
Вопрос: На сколько % увеличилась EBITDA год к году по МФСО 17 ?
Правильный ответ: 48,8%
Скорее всего, все 4 ответа у вас будут неправильные5. Улучшение процесса создания чанков
Чтобы использовать более продвинутые стратегии нарезки документов, отправим запрос к API CompressaChunking. Мы будем использовать тот же размер чанков (1000 символов) и укажем дополнительные настройки, доступные в этом API. Полный список параметров можно посмотреть в документации.
# Указываем URL и заголовки авторизации
url = "https://compressa-api.mil-team.ru/v1/layout"
headers = {
"Authorization": f"Bearer {os.environ['COMPRESSA_API_KEY']}",
"accept": "application/json",
}
# Указываем наш PDF файл
files = {"files": open("mvideo_report.pdf", "rb")}
# Сохраняем 2 настройки из инструмента langchain и прописываем остальные
data = {
"xml_keep_tags": "false",
"output_format": "application/json", # Формат ответа: JSON
"coordinates": "false", # Нам не нужны координаты элементов
"strategy": "fast", # Используем быструю стратегию обработки документа, т.к. можно скопировать текст из файла
"chunking_strategy": "by_title", # Используем заголовки для нарезки чанков
"combine_under_n_chars": 800, # Объединеняем, если меньше 800 символов
"max_characters": 1000, # Максимум 1000 символов на чанк
"multipage_sections": "false", # Не разрешать чанкам пересекать несколько страниц
"overlap": 20, # Добавление соседних символов к чанку
"starting_page_number": 1, # Начать с первой страницы
"languages": ["rus", "eng"] # Языки, которые используются в документе
}
# Выполняем запрос к API
response = requests.post(
url,
headers=headers,
files=files,
data=data
)
# Сохраняем результаты и проверяем полученные чанки
result = response.json()
print(str(result)[:1000])
# Преобразуем ответ API в формат, понятный для Langchain
chunks = []
for item in result:
# Создаем объекты Document для каждого чанка
text = item['text'] # Извлекаем текст из JSON
chunk = Document(page_content=text)
chunks.append(chunk)
# Вывод всех чанков после нарезки
for i, chunk in enumerate(chunks):
print(f"Чанк {i+1}:\n{chunk.page_content}\n")
6. Повторное тестирование и оценка результатов
Можно заметить, что чанки теперь стали лучше соответствовать структуре презентации. Заполним новое векторное хранилище:
# Создаем и заполняем новое векторное хранилище
vectorstore2 = FAISS.from_documents(chunks, embeddings)
print("Векторное хранилище успешно создано")
# Создаем механизм поиска нужных чанков в новом хранилище
retriever2 = vectorstore2.as_retriever(search_type="similarity", search_kwargs={"k": 1})
rag_chain2 = create_retrieval_chain(retriever2, document_chain)
def ask_question2(question):
response = rag_chain2.invoke({"input": question})
return response["answer"]
print("\nИспользование RAG пайплайна:")
for question in questions:
print(f"\nВопрос: {question}")
print(f"Ответ RAG: {ask_question2(question)}")
Сравним полученные результаты с правильными ответами:
Вопрос: Что было в мае?
Правильный ответ: Группа стала крупнейшим оператором электронных отходов в России и ключевым партнёром первого в России комплекса заводов по переработке электроники «Корпорации Экополис».
Вопрос: Когда стартовали продажи бренда Casarte?
Правильный ответ: В декабре
Вопрос: На чем планирует фокусироваться компания в области гарантийного и пост-гарантийного обслуживания?
Правильный ответ: Группа планирует дополнительно фокусироваться на предостав- лении широкого спектра специализированных инструментов – продлённой гарантии, товарных страховок
Вопрос: На сколько % увеличилась EBITDA год к году по МФСО 17 ?
Правильный ответ: 48,8%
Заметим, что теперь �все ответы правильные. Благодаря грамотной нарезке документов на чанки, мы не разрывали контекст между отдельными кусками, поэтому LLM получила правильную, полную информацию и смогла дать точный ответ на вопрос.Вы можете также улучшить точность поиска с помощью модели CompressaRerank, которая дополнительно приоритизирует найденные отрывки под запрос пользователя. Для этого мы подготовили специальный гайд.
Если вы хотите глубже погрузиться в Embeddings и понять, как технически устроен семантический поиск - посмотрите еше одно наше практическое руководство.