Finetuning
Compressa provides the feature of low-effort models fine-tuning via LoRA/QLoRA adapters.
Fine-tuning allows to increase quality for business cases, focus model on some topic or introduce format to the output data.
Preparing data
Compressa allows to fine-tune models on chat data. To start the process you should:
- Prepare conversation examples
- Format them into JSON Lines format with the next content on each line:
{
"messages": [
{
"role": "user",
"content": "<USER MESSAGE 1>"
},
{
"role": "bot",
"content": " <BOT'S RESPONSE>"
},
{
"role": "user",
"content": "<USER MESSAGE 2>"
},
{
"role": "bot",
"content": " <BOT'S RESPONSE2>"
},
]
}
Each dialog can have any number of messages.
Dataset should have at least 100 samples.
Training
When data is prepared you can start training in Compressa Finetuning UI or with REST API.
Documentation for REST API can be found at Management API documentation page.
Compressa Finetuning UI
URL: http://localhost:8080/finetune/
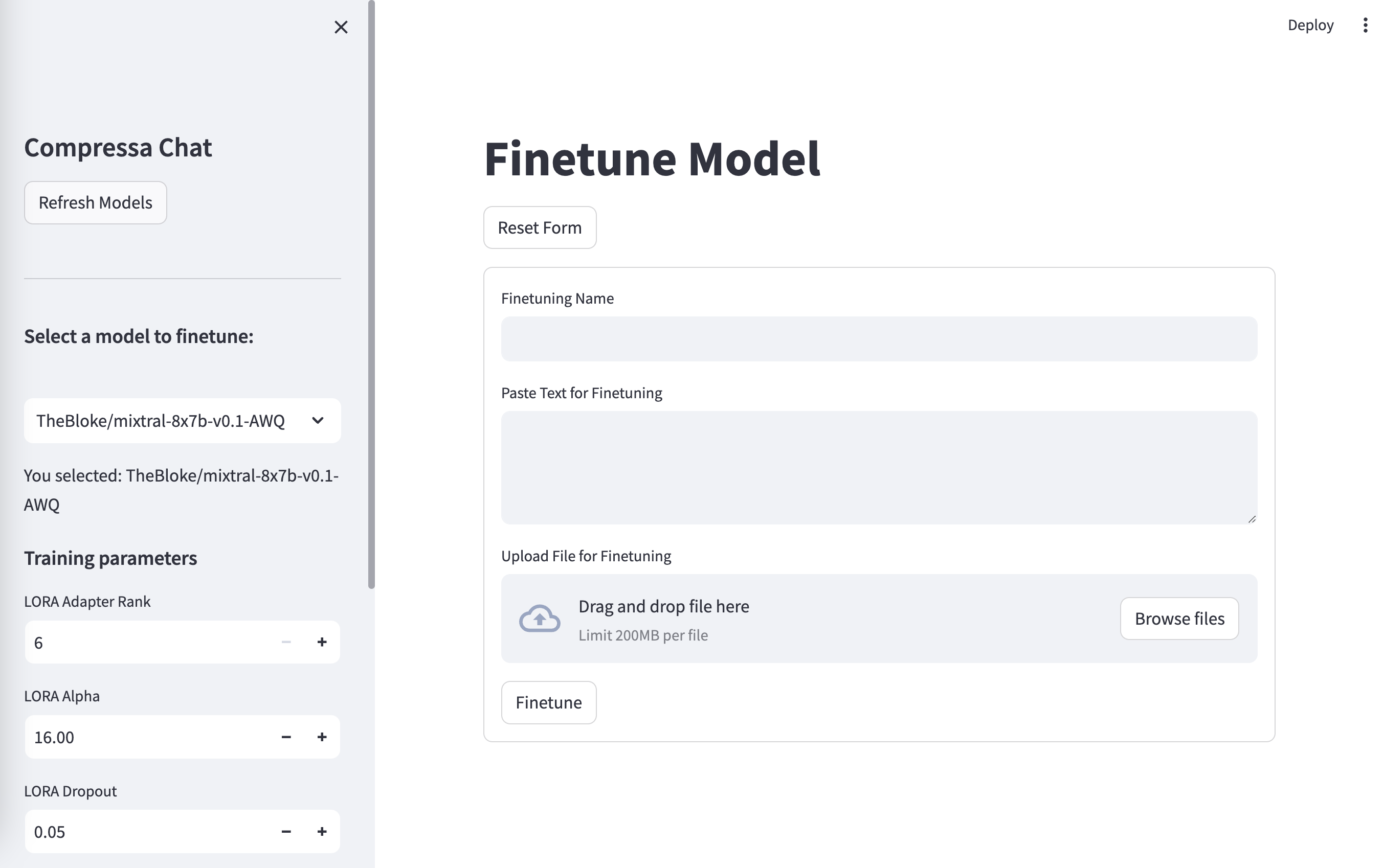
To finetune model using UI you should:
- Select a model in the left panel
- Fill-in the name of your finetune
- Upload
jsonlfile to the form - Click the Finetune button
Then you can track training process in AIM dashboard.
Dashboard can be opened by clicking Training Dashboard.
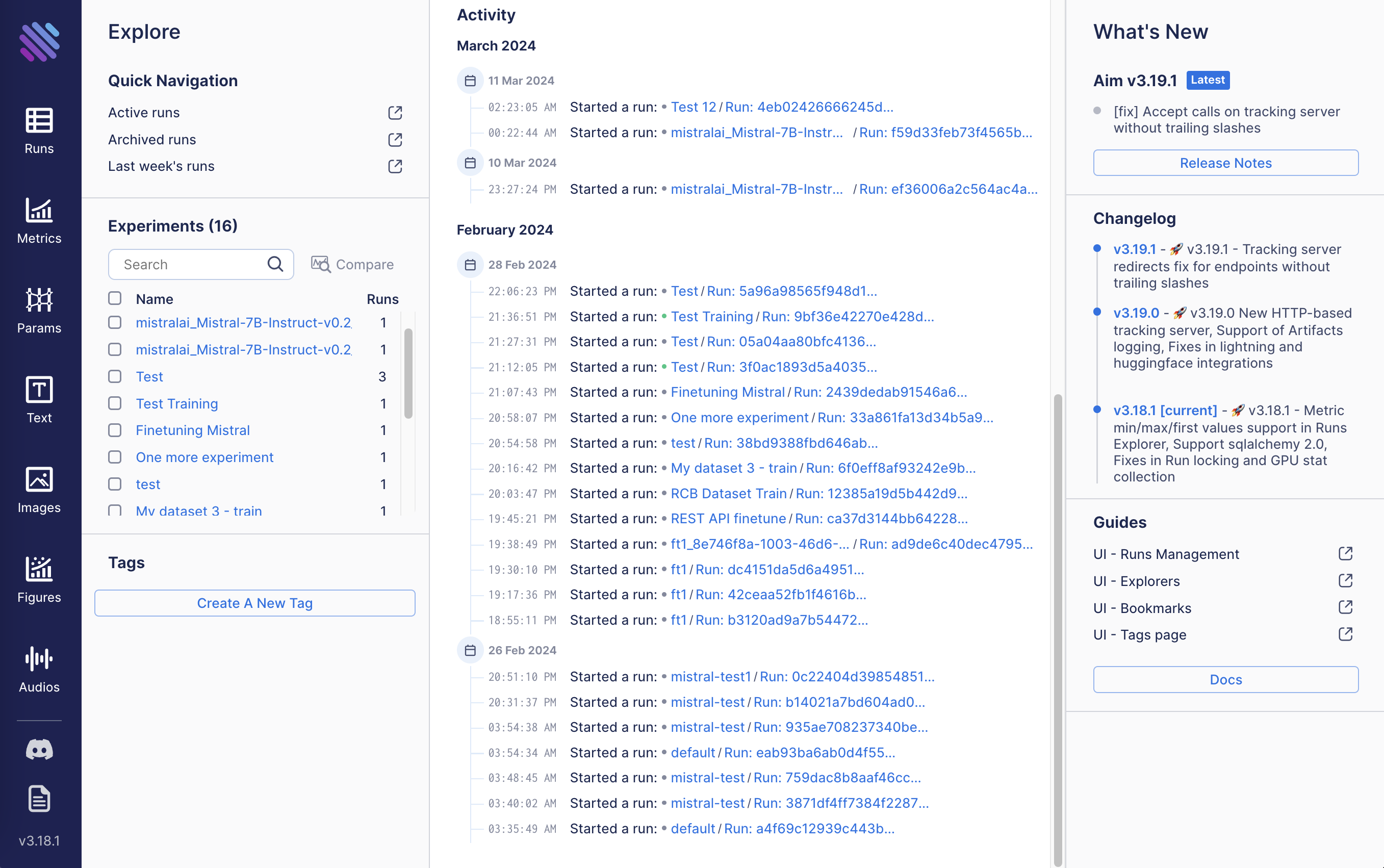
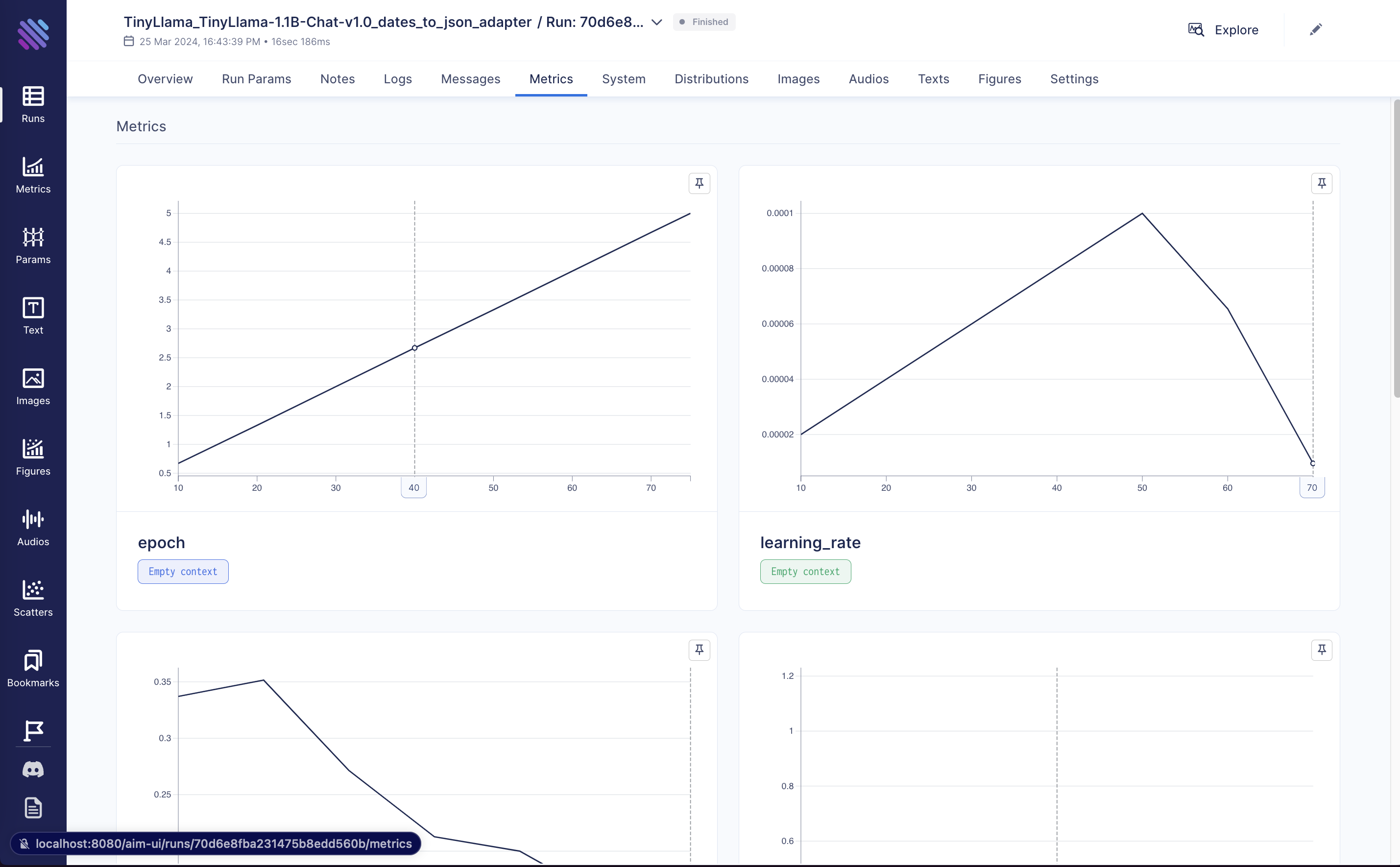
The dashboard allows to choose run by the provided name and see metrics:
Deploy
When training process is finished, adapter can be deployed in Compressa for inference.
The full instruction for deployment can be found at page.